앞의 방법들처럼 action value estimates를 이용하여 이를 토대로 action selection을 진행하는 방법 대신, 별도의 또다른 metric을 이용하는 방법들도 있습니다.
action a를 선호하는 Preference Ht(a)를 정의합니다.
Ht(a)는 value로 표현한 함수가 아닌, 임의로 정의한 action에 대한 선호도 입니다.
action을 선택할 때, action별 Ht(a)을 비교하여 선호도가 높은 action위주로 시행하며, action을 선택할 확률 πt(a)를 Preference Ht(a)에 대한 softmax 함수의 형태로 정의합니다.
Pr{At=a}≐∑b=1keHt(b)eHt(a)≐πt(a)
초기 선호도가 모두 동일한 상태(e.g., H1(a)=0, for all a)에서 action selection을 진행해 가며 gradient ascent를 이용하여 전체 성능을 극대화하는 Ht(a)를 찾을 수 있습니다.
전체 성능에 대한 measure로는 expected reward E[Rt]=x∑πt(x)q∗(x)를 이용하고, 이를 토대로 action preferences updating 알고리즘을 만들 수 있습니다.
Ht+1(a)≐Ht(a)+α(Rt−Rtˉ)(1At=a−πt(a)),∀a
α>0은 step-size parameter(learning rate)이며, Rtˉ∈R은 time t까지의(t를 포함한) reward 평균으로, baseline으로서 기능합니다. (지금까지의 성능과 비교하여 action 평가의 기준이 됩니다.)
Rtˉ≐t1i=1∑tRi
앞의 방법들과 혼동하지 말아야 할 부분은, Qt(a)값이 action마다 할당된 값이었던 것과 비교하여, Rtˉ는 global한 값이라는 부분입니다. reward의 평균이라는 부분에서 동일한 metric으로 오해할 수 있는데, Qt(a)는 “action a의 reward 총합을 a가 선택한 횟수로 나눈 값”이고, Rtˉ는 “모든 action들에 대한 전체 reward 총합을 time step으로 나눈 값” 입니다. 때문에, 당연히 incremental update를 진행할 때에도 Qt(a)와는 달리 action이 시행된 횟수가 아닌 time step을 기준으로 진행하여야 합니다.
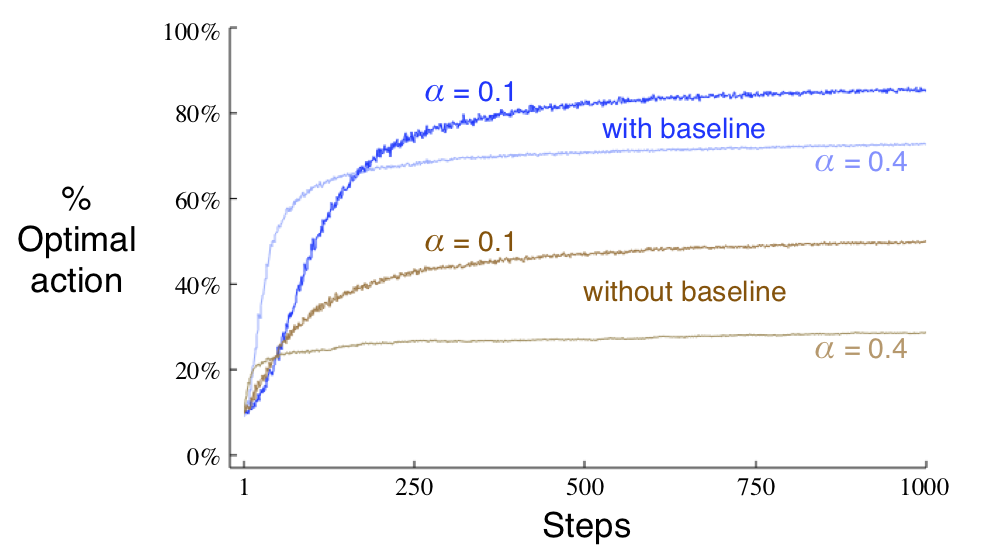
10-armed testbed에서 학습한 결과는 아래 그래프와 같습니다.
이전과 같이 간략화한 문제에 대입하여 과정을 살펴보면 다음과 같습니다.
α=0.5로 계산합니다.
다음에 선택될 action이 deterministric하지 않고 stochastic하다는 부분에 있어 타 방법들과 큰 차이가 있습니다.
위의 방법들은 평가의 기준이 되는 메트릭이 가장 높은 action만 결정적으로 선택하여도 학습의 진행에 큰 문제가 없지만,
이 방법으로는 그런 식으로 진행할 경우 학습이 진행되지 않기에 불안정하다고 느껴질 수도 있습니다.
baseline Rtˉ에 대한 보다 깊은 이해를 위해서는 알고리즘의 유도과정을 살펴봐야 합니다. 어려운 내용은 아니나, 다소 길기에 차후 살펴보도록 하겠습니다.