Sutton RL - Ch1. Multi-armed Bandits (1)
Posted on
A -armed Bandit Problem

one-armed bandit은 옆에 거대한 막대가 달려있어, 이를 당겨 시행하는 슬롯머신을 말합니다.
각기 다른 확률적 보상이 책정되어있는 이러한 one-armed bandit을 여러대를 선택적으로, 반복적으로 시행하여 최대한의 보상을 획득하는 문제를 multi-armed bandit problem 이라고 합니다.
일반화하면, -armed bandit problem은 개의 action에 대하여 반복적으로 선택을 시행한 뒤 매 선택마다 확률분포적으로 책정된 reward를 받는 경우, 일정 time step을 거친 뒤, reward의 총계를 최대화하는 문제라 할 수 있습니다.
각각의 action에 따라 reward 기대값이 존재하며, 이를 action에 대한 value라 부릅니다.
time step 에서의 action을 , reward를 라 할 때, action 의 value는 와 같이 주어집니다.
각 action에 대한 value값을 알 수 있다면 매번 value가 가장 큰 action을 선택하여 -armed bandit problem을 푸는 것은 간단하지만, 이 값이 주어지지 않은 상태에서 최적의 action을 찾는 것이 문제이기 때문에, step 에 대한 action 의 estimated value를 라 정의하며, 학습을 진행하며 이 값을 에 가깝게 가져갑니다.
The Exploration / Exploitation Dilemma
로 근사하여 문제를 푸는 경우를 생각해봅시다. (action-value estimates)
time 에서의 greedy action을 라고 정의할 때,
일 때 exploiting을,
일 때 exploring을 하게 됩니다.
다시말하자면 exploiting은 현재까지의 시행을 통하여 얻은 근사적 value를 통하여 최적의 해를 선택(greedy), reward를 높이는 과정이며 exploring은 근사적 value가 가장 높지 않은 해를 선택(non-greedy), 시행횟수를 증가시켜 estimated value를 real value에 가깝게 가져가는 과정입니다.
exploiting과 exploring을 동시에 진행할 수는 없으나, 둘 모두가 최종 보상을 크게 하기 위해 필요한 과정입니다. 문제의 정의에 따라 exploiting과 exploring의 비율을 어떻게 가져가는 것이 optimal한가는 다릅니다.
예를 들자면 multi-armed bandit problem의 경우, time step에 따라 real value가 변하지 않을 경우 exploring의 비율을 time step에 따라 줄여나가는 편이 좋을 것이라 직관적으로 생각할 수 있습니다. 반대로, time step에 따라 real value가 변할 경우, exploring은 time step이 경과한 후에도 상당한 빈도로 진행되어야 할 것입니다.
exploiting과 exploring의 빈도를 합리적으로 결정하기 위한 방법들이 논의되어왔으며, 이 방법들이 이 단원의 핵심이 되는 내용 입니다.
Action-value Methods
action-value estimates ()를 학습하기 위한 방법들을 말합니다.
한 예로, action-value를 sample averages로 근사하는 방법이 있습니다.
sample-average estimetes는 action이 무한히 행해질 경우 true value로 수렴하게 됩니다.
The 10-armed Testbed
이후 살펴보게 될 학습방법들은 아래의 동일환경에서 시행한 결과를 바탕으로 설명합니다.
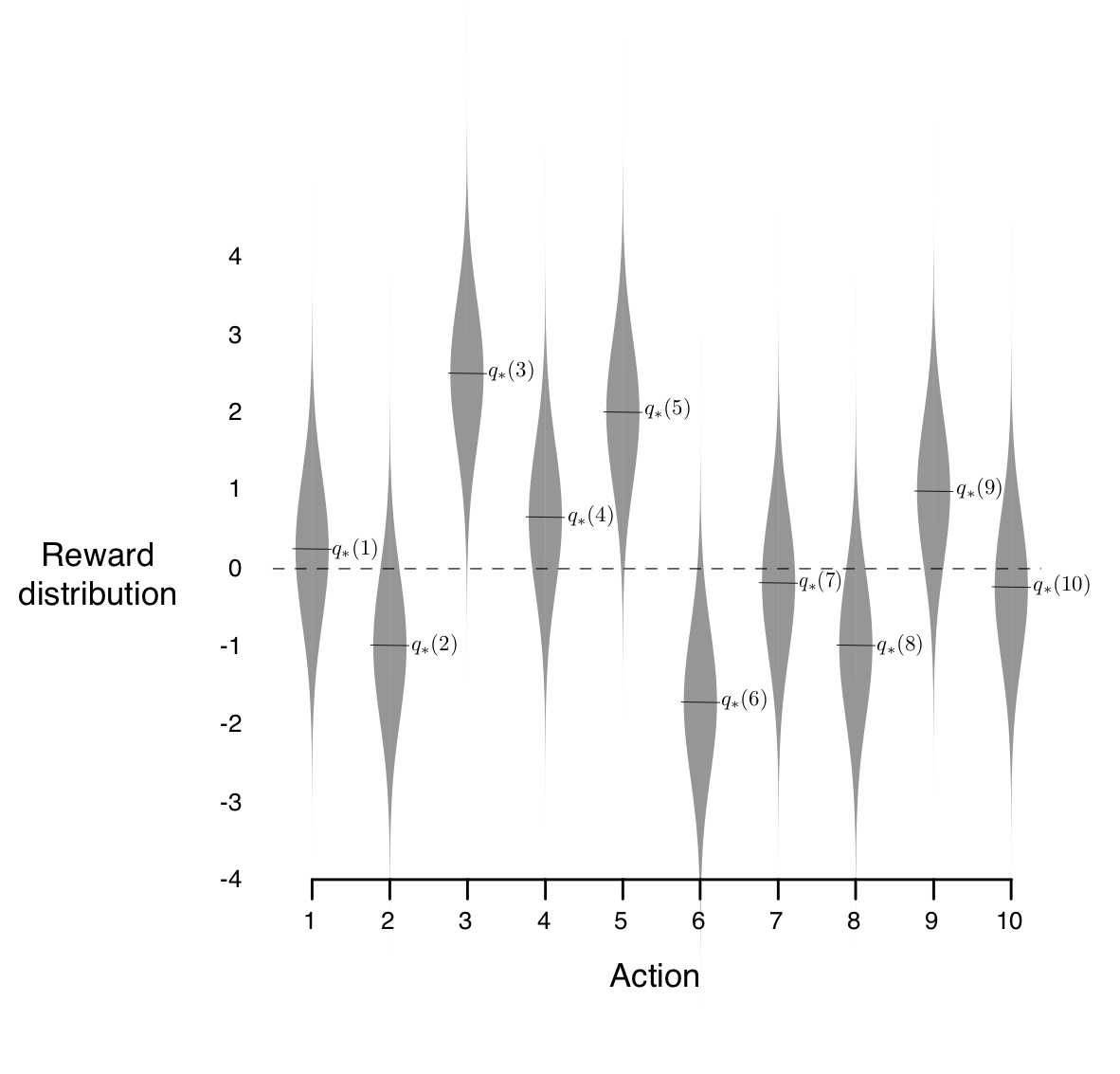
값은 표준정규분포에서 랜덤하게 샘플링하였으며
매 action은 평균 , 표준편차 1의 정규분포를 통해 랜덤한 reward를 리턴합니다.
1000step간 진행된 결과를 하나의 시행으로 보며, 각각의 시행을 2000회씩 반복하여 통계적으로 성능 및 경향성을 파악합니다.
Incremental Implementation
매 시행마다 reward를 다시 처음부터 다 더한 뒤 평균내어 값을 계산할 필요가 없기에, (이전 step에서의 값)를 이용하여, 마지막 increment분만 더해주는 방식으로 누적해나가는 방식으로 계산합니다.
책에서는 다소 길게 설명하고 있지만 당연하고, 간단한 내용입니다.
Averaging을 learning/updating의 형태로 바꾸었다는 의의가 있으며, 이러한 형태가 learning/update rules의 표준형 입니다.
를 이 방법으로 구할 때 오해하지 말아야 할 부분은, 매 time step마다 모든 actions에 대하여 이 방법으로 업데이트를 하는 것이 아니라, 시행된 action에 대해서만 업데이트를 진행한다는 점입니다. 값 또한, action이 시행된 횟수이지 time step이 아님에 유의하여야 합니다.
Tracking a Nonstationary Problem
true action values가 시간이 지남에 따라 변화할 경우, 우리는 이를 nonstationary problem이라 합니다.
이 경우, sample averages를 action value estimates로 잡는 것에는 문제가 있습니다.
sample averages의 경우
에서 보듯 time step이 길어짐에 따라 updating되는 incremental부분이 점점 작아지는 형태로 되어 있고, 따라서 변화하는 true action value값에 대해서는 민감하게 반응하지 못하는 결과가 발생합니다.
이를 극복하기 위하여 “exponential, recency-weighted average” 의 필요성이 대두됩니다.
“exponential, recency-weighted average” 는 다음과 같은 방법으로 계산합니다.
true action value의 변화 속도에 따라 parameter 값을 adaptive하게 설정합니다.
1에 가깝게 설정할 경우, decay속도가 빠르고, 최근의 경향성에 weight를 준 학습법이 되고, 0에 가깝게 설정할 경우 decay속도가 느리며, 과거의 경향성에 weight를 준 학습법이 됩나다.
Nonstationary Problem에 대하여 설명하고는 있지만, 개념적으로 짚고 넘어가는 것일 뿐이고 뒤에 논의할 방법들에서는 nonstationary가 아닌 stationary problem들 위주로 논의를 하고, sample averages를 이용합니다.