Neural Architecture Search
Posted on
Neural Architecture Search
Introduction: What is NAS?
Neural Architecture Search (NAS) is an approach for automating the design of deep neural networks. Instead of relying on human intuition and trial-and-error, NAS algorithms explore a predefined search space to find architectures that perform well on a given task.
A typical NAS pipeline involves:
- Search Space: Defines the types of operations and connections allowed.
- Search Strategy: Determines how the space is explored (e.g., reinforcement learning, evolution, gradient descent).
- Evaluation Strategy: Estimates the performance of candidate architectures.
DARTS: Differentiable Architecture Search
DARTS (2018) introduced a gradient-based NAS framework by relaxing the discrete architecture search space into a continuous one. Each operation between nodes is represented by a weighted mixture:
Here, are architecture parameters learned via gradient descent.
This allows joint optimization of:
- : network weights
- : architecture weights
via bi-level optimization:
How DARTS Optimization Works in Practice
Solving the bi-level optimization problem above directly is intractable. The inner optimization requires finding the optimal weights for every potential architecture , which would mean fully re-training the network every time we update . This is computationally prohibitive.
To overcome this, DARTS employs a two-part approximation:
1. Approximate with a Single Gradient Step
Instead of fully training the network to get , DARTS approximates it using , which is the result of just a single training step:
Here, is a learning rate for this single “inner” update. Now, the goal is to update by calculating the gradient .
2. Approximate the Hessian-vector Product with Finite Differences
Applying the chain rule to get the gradient for introduces a second-order derivative (a Hessian matrix) that is also expensive to compute:
The costly term is the Hessian-vector product . DARTS sidesteps this by using a finite difference approximation:
where , and is a small scalar. This allows estimating the architectural gradient with only two forward passes and two backward passes, avoiding the explicit Hessian computation.
By combining these approximations, DARTS can efficiently find a promising architecture. However, these approximations, while efficient, are also a source of instability and contribute to some of the issues listed below.
While efficient, DARTS suffers from issues like:
- Overfitting to weight-sharing artifacts
- Architecture collapse to trivial choices
- Lack of generalization guarantees
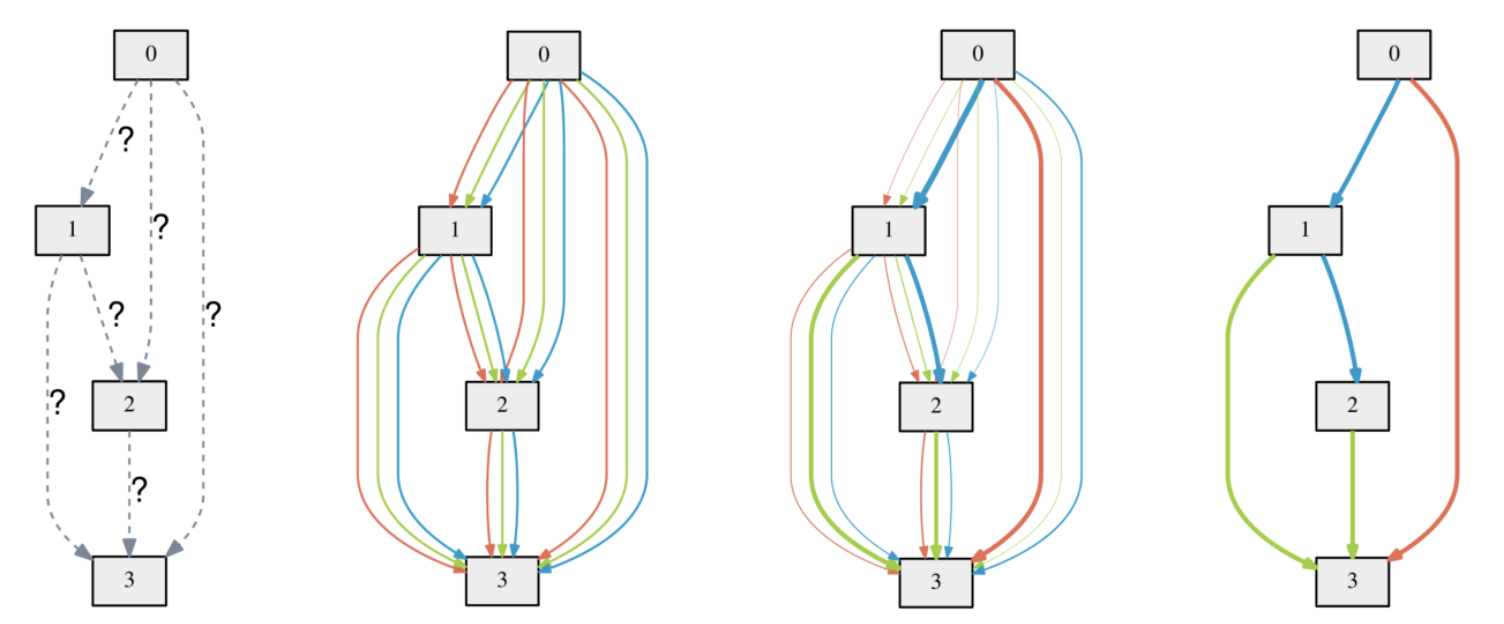
The figure below is a schematic of the architecture of DARTS for cnn and rnn restored based on the paper.
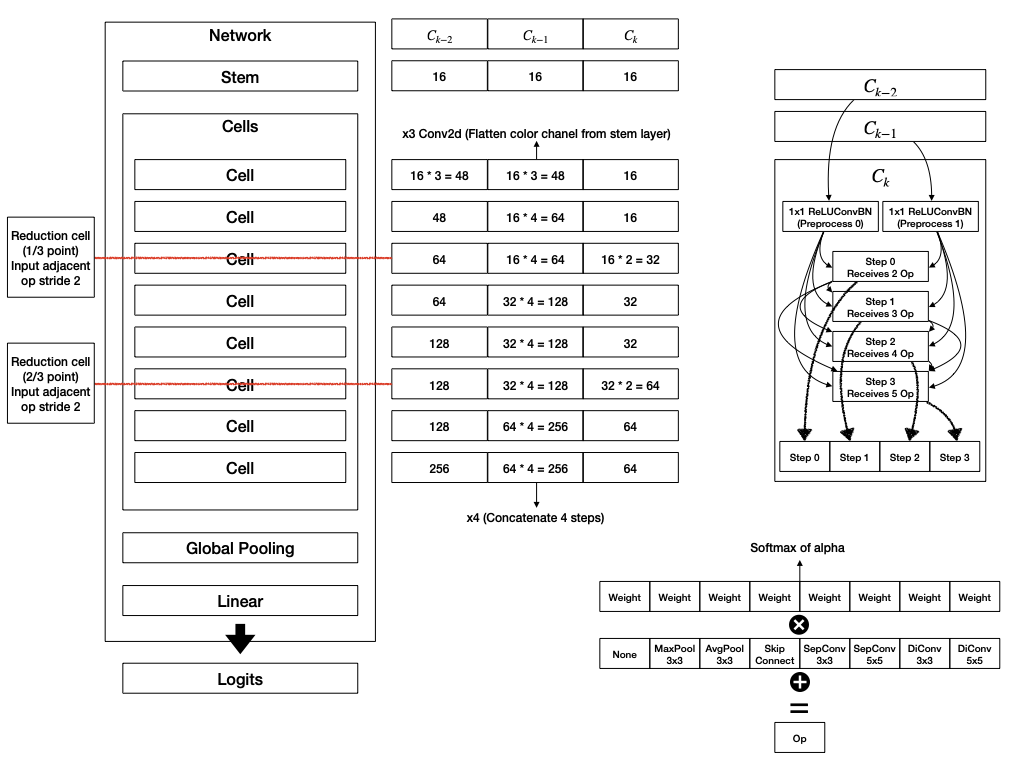
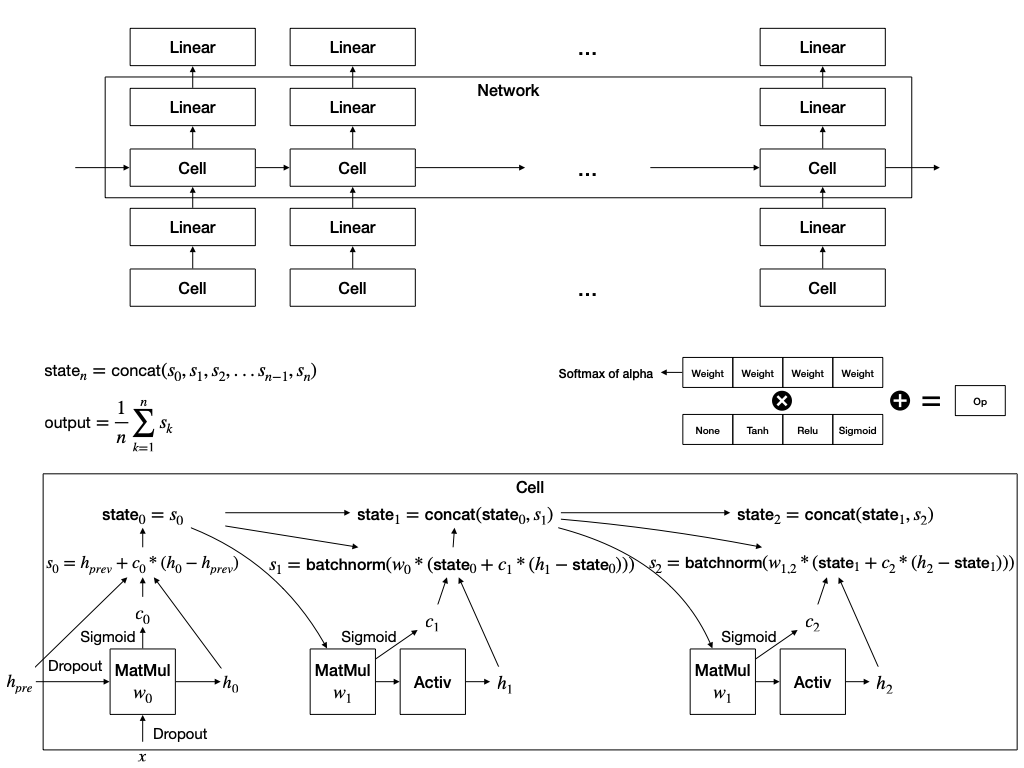
XNAS: NAS with Expert Advice (Nayman et al., 2019)
To overcome DARTS’ limitations, XNAS (Expert Advice NAS) frames NAS as an online learning problem using the Follow-the-Regularized-Leader (FTRL) algorithm. This provides theoretical guarantees and improved stability.
Key Idea
Treat each architecture as an expert, and use online learning with expert advice to learn a probability distribution over the experts (architectures).
- Let be the set of all possible architectures (e.g., combinations of operations on a DAG).
- At each round , the algorithm selects a distribution over .
- One architecture is sampled and trained.
- The resulting loss is used to update the distribution.
FTRL Objective
At each round , FTRL chooses as:
- : loss vector over all experts at round
- : regularization term (e.g., negative entropy)
- : learning rate
- : probability simplex over
This balances exploitation (low cumulative loss) and exploration (via regularization).
The Power of Exponentiated Gradient (EG) Update
A key difference from DARTS lies in how the architecture parameters are updated. The EG update rule in the algorithm, , seems different from standard gradient descent, but it’s actually its natural counterpart in the probability space.
Let’s see why.
In DARTS, updates are additive on the logits :
The unnormalized scores (before softmax) are typically .
If we apply the gradient update to , the new scores become:
Using the property of exponents, this can be rewritten as:
Since the reward is defined as the negative loss gradient (), we arrive at the EG update rule:
This shows that an additive update on logits is equivalent to a multiplicative update on the unnormalized scores. By using this form directly, XNAS ensures that the update magnitude depends on the reward, not the current weight. This prevents experts with small weights from getting stuck and allows for more robust exploration.
Practical Implementation in XNAS
Directly enumerating all architectures is infeasible, so XNAS:
- Decomposes the architecture into local decisions (e.g., operation choices on each edge)
-
Uses a product distribution over edges:
Let be the set of edges, and each edge has candidate operations .
Then:
where is the categorical distribution over .
- Updates each using the FTRL rule independently.
Online-to-Batch Conversion
After rounds of online training, the final architecture can be:
- Sampled from the learned distribution
- Or chosen as the argmin of cumulative loss across rounds
Regret Guarantee
XNAS provides a regret bound of:
This means that the algorithm asymptotically performs as well as the best fixed architecture in hindsight.
Wipeout: Principled Pruning in XNAS
In the XNAS framework, Wipeout refers to a pruning mechanism where operations with extremely low selection probabilities are permanently removed. This is not an ad-hoc rule; the pruning threshold is derived from a rigorous worst-case analysis.
The goal is to prune an expert if it can provably never catch up to the current best expert, even under the most favorable conditions. Let’s walk through the derivation.
- Setup: At round , the current best expert has weight . We are considering pruning expert with weight . There are rounds left. The reward magnitude is bounded by .
- Best Case for the Underdog: What is the maximum possible weight for expert at the final round ? This occurs if it receives the maximum possible reward () in every remaining round.
- Worst Case for the Leader: What is the minimum possible weight for the current leader? This occurs if it receives the minimum possible reward () in every remaining round.
- The Pruning Condition: We can safely prune expert if its best possible outcome is still worse than the leader’s worst possible outcome.
- Deriving the Threshold: By rearranging the inequality to solve for , we get the final Wipeout condition: The right-hand side is precisely the threshold . This makes Wipeout a theoretically sound strategy for efficiently sparsifying the search space.
Note: This is distinct from the notion of unintended probability collapse (common in DARTS); XNAS’s wipeout is a designed strategy for efficient NAS.
Conclusion
XNAS reformulates NAS from a differentiable optimization problem into an online decision-making one, with strong theoretical foundations. Unlike DARTS, it avoids weight-sharing artifacts and provides provable regret bounds for the selected architecture. Through principled techniques like the Exponentiated Gradient update and theoretical Wipeout, it achieves a more stable and robust search process.
This approach bridges the gap between learning theory and architecture search, and opens new directions for stable, theoretically grounded NAS.
References
- Nayman, Niv, et al. ”XNAS: Neural Architecture Search with Expert Advice.” arXiv preprint arXiv:1910.00722 (2019).
- Liu, Hanxiao, et al. ”DARTS: Differentiable Architecture Search.” arXiv preprint arXiv:1806.09055 (2018).