HVAC System Optimization
Posted on
Optimizing Data Center HVAC Systems with Reinforcement Learning
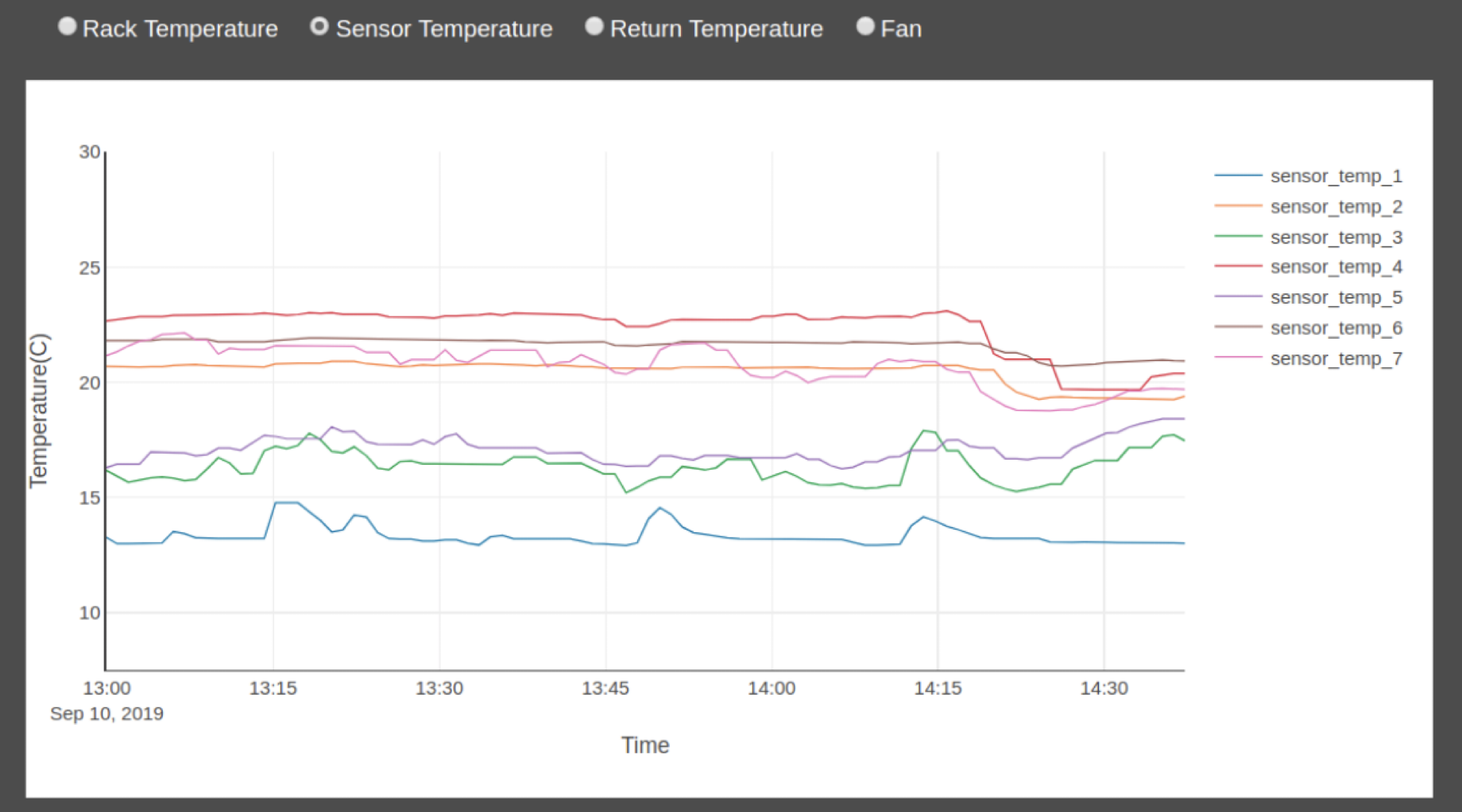
Background
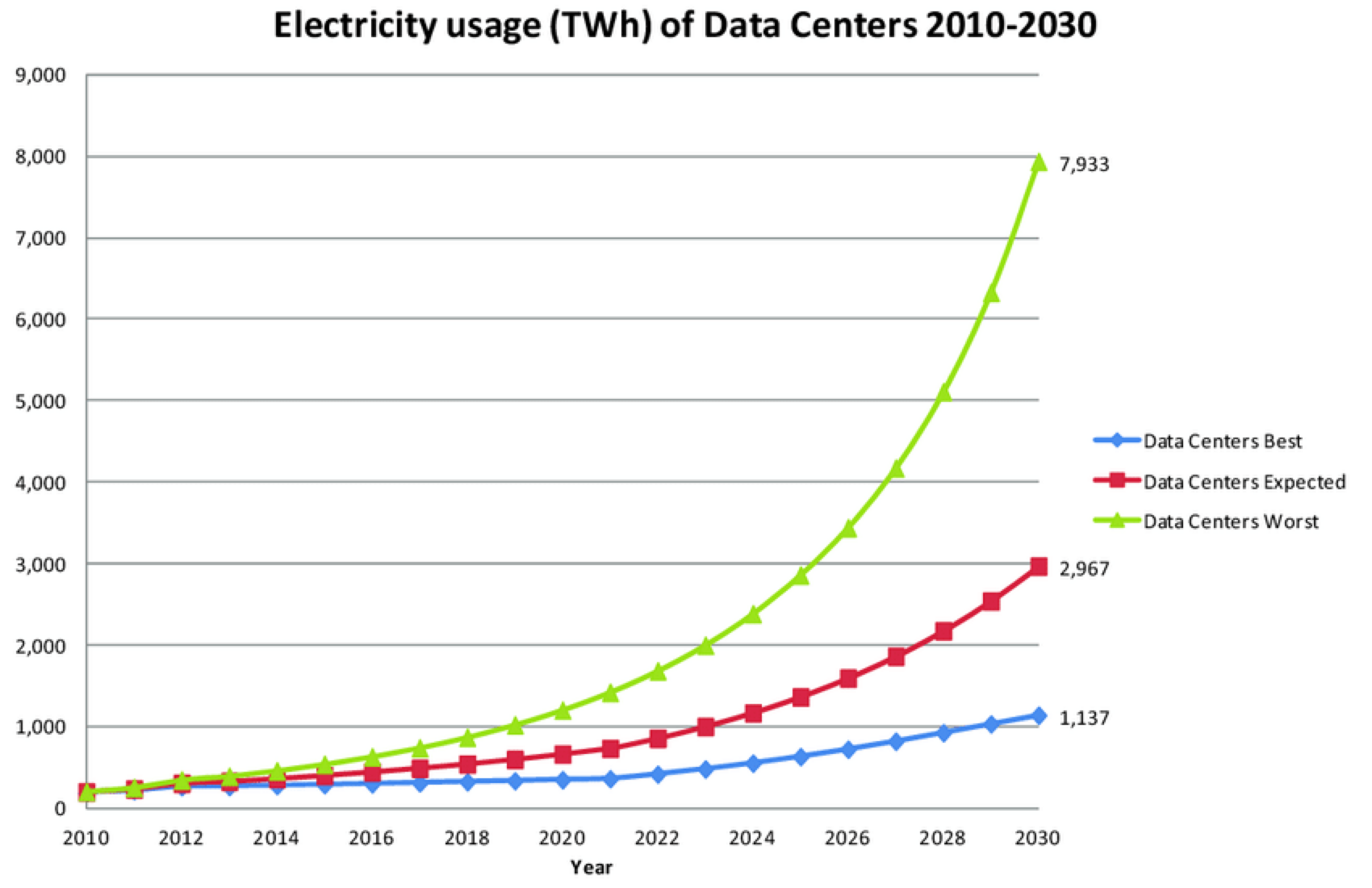
As data centers continue to scale, their cooling systems consume a significant amount of energy. In many facilities, the HVAC (Heating, Ventilation, and Air Conditioning) system accounts for a large portion of total electricity usage. To ensure optimal performance, server temperatures must stay within a narrow range (e.g., 22.5°C), while simultaneously minimizing Power Usage Effectiveness (PUE).
This project explores the use of Deep Reinforcement Learning (DRL) to automate and optimize HVAC system control, achieving both energy efficiency and thermal stability.
Problem Setting
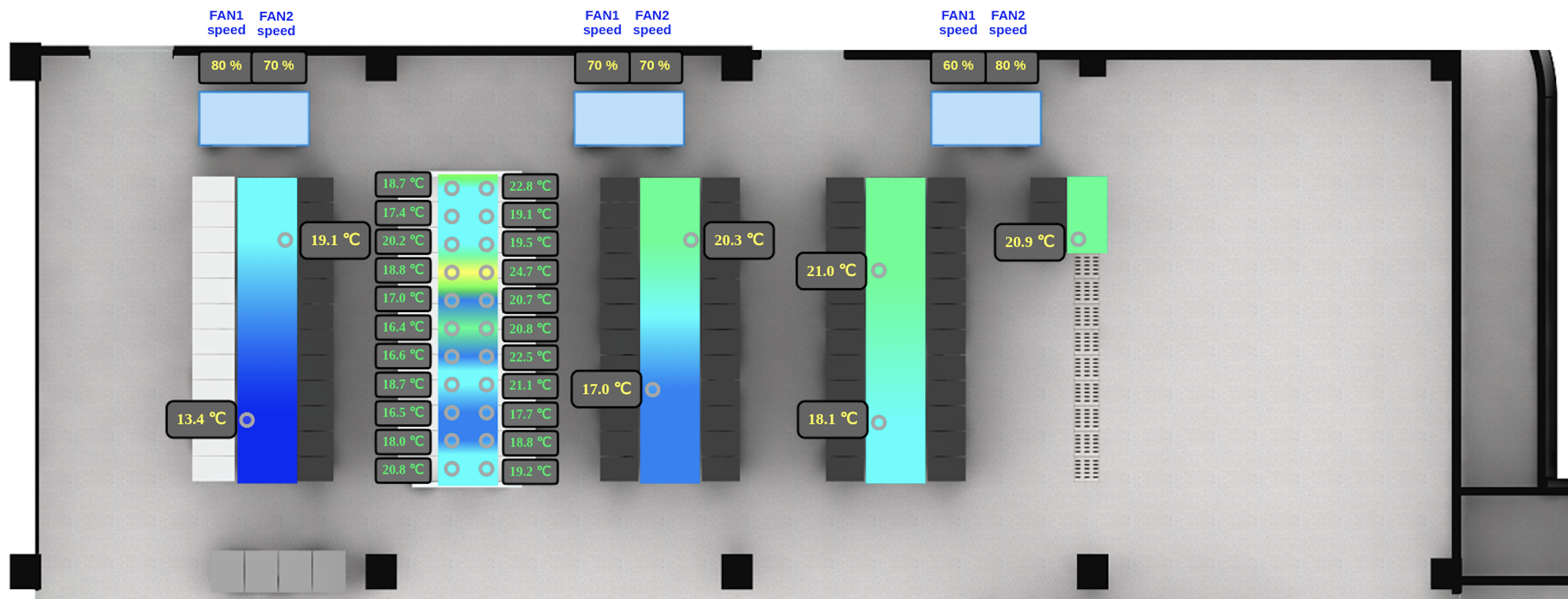
- Objective: Keep server room temperatures within the safe range while minimizing electricity consumption.
-
Environment:
- Real-time temperature sensors (multiple spots)
- CRAC (Computer Room Air Conditioning) return air temperature
- CRAC fan controllable via agent actions
-
Challenges:
- Partial observability (POMDP)
- Long response times (low reactivity)
- Hard safety constraints (temperature violation is unacceptable)
Proof of Concept (PoC)
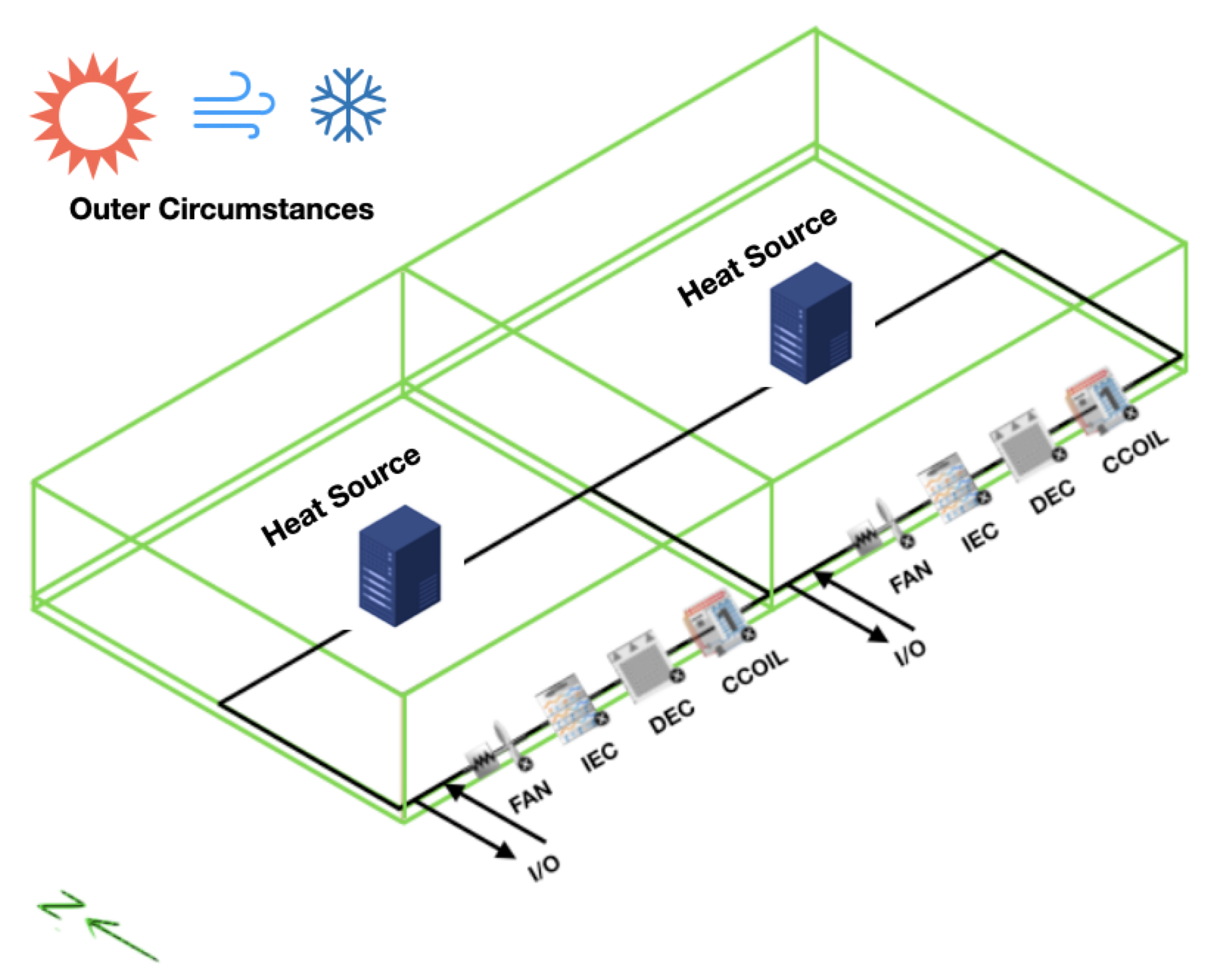
To validate the feasibility of RL control in real-world HVAC systems, we used a simulator-based approach.
- Simulator: EnergyPlus with an official 2Zone DataCenter HVAC model
- Communication: POSIX named pipes were used to interface the agent with the simulator
- RL Agent: Trained using a combination of model-based and model-free techniques (see below)
Core Techniques
1. Probabilistic Dynamics Modeling (MDN)
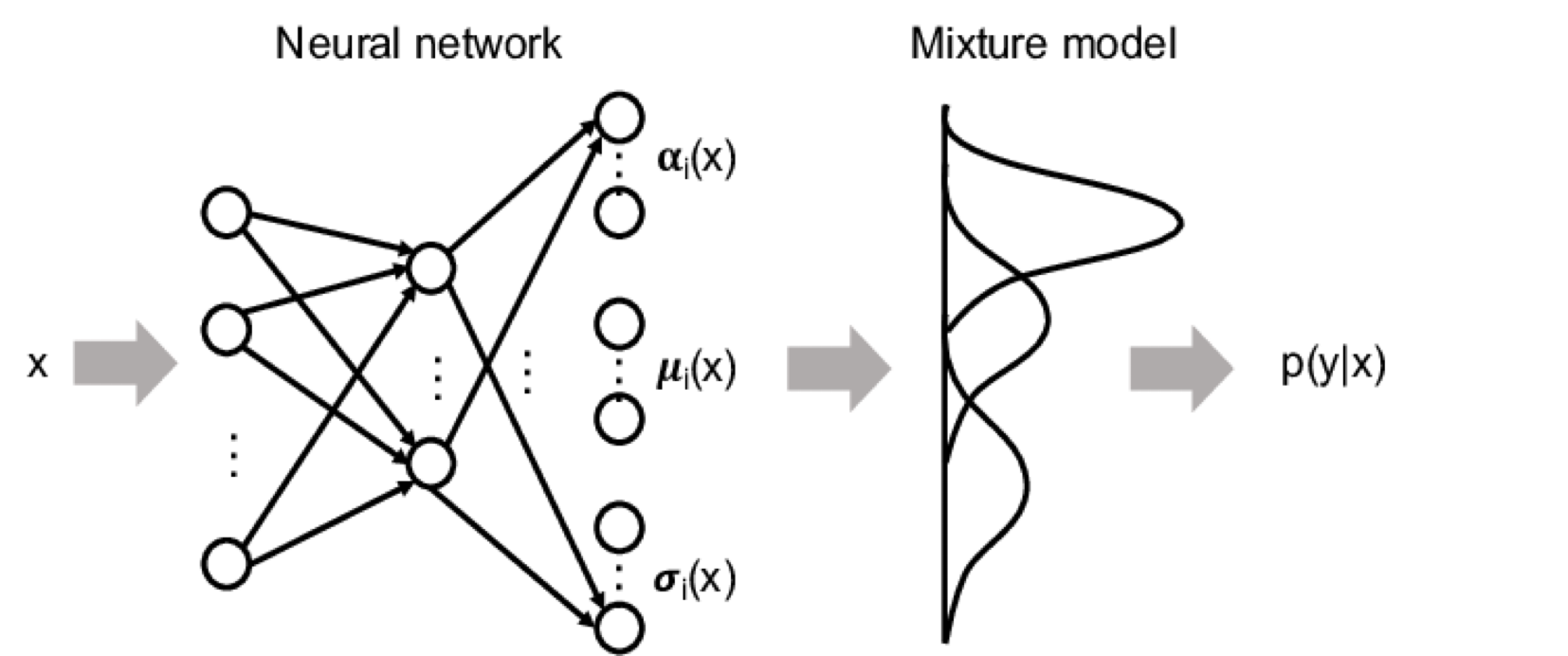
To better capture the stochastic nature of the environment, especially under partial observability, I trained a Mixture Density Network (Christopher M. Bishop, 1994) as the dynamics model. This allowed our agent to handle multi-modal transition distributions more accurately.
This idea was inspired by the use of MDNs in World Models, where multi-modal transitions were crucial to modeling generative trajectories.
2. Model-Based Model-Free combined RL with Dyna Style Learning
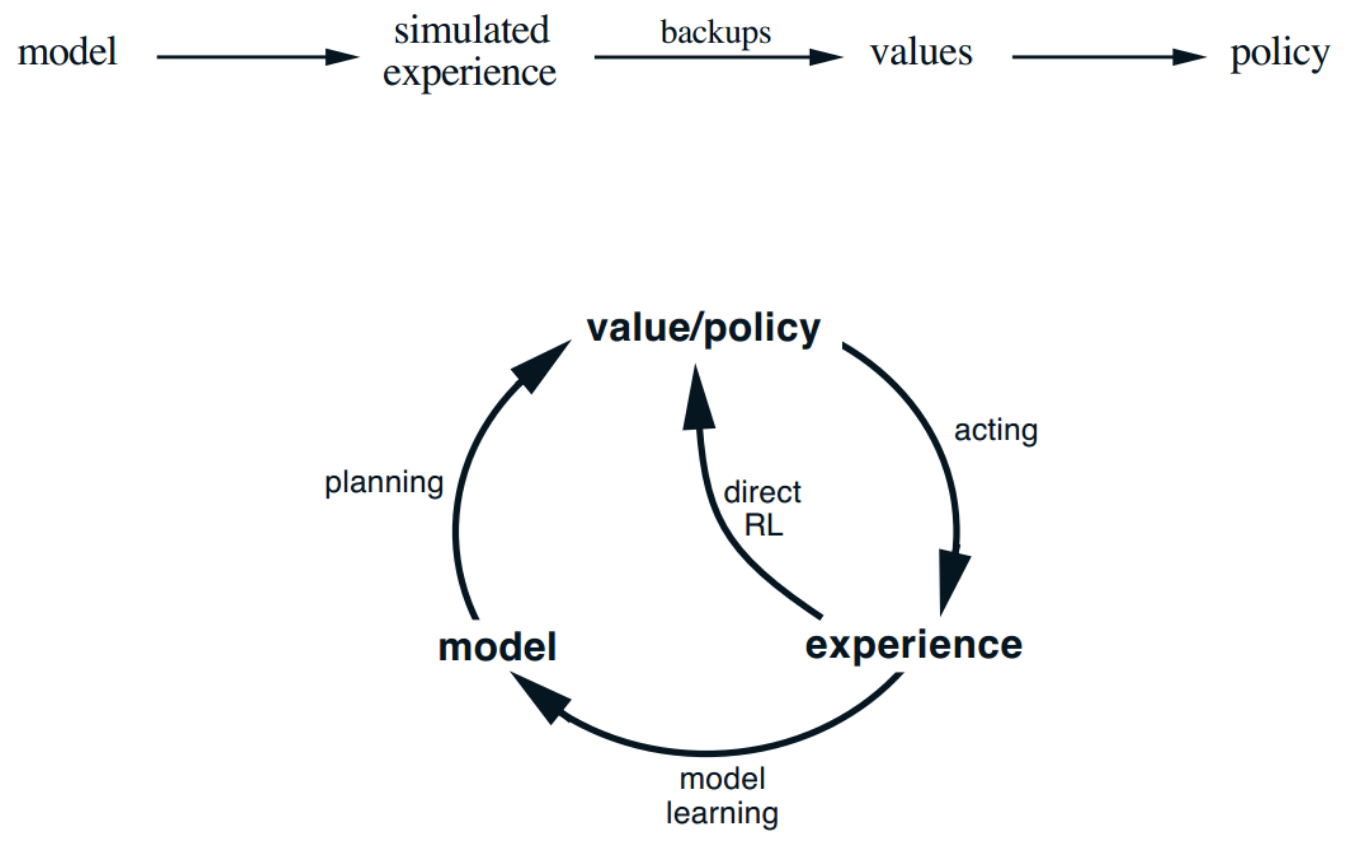
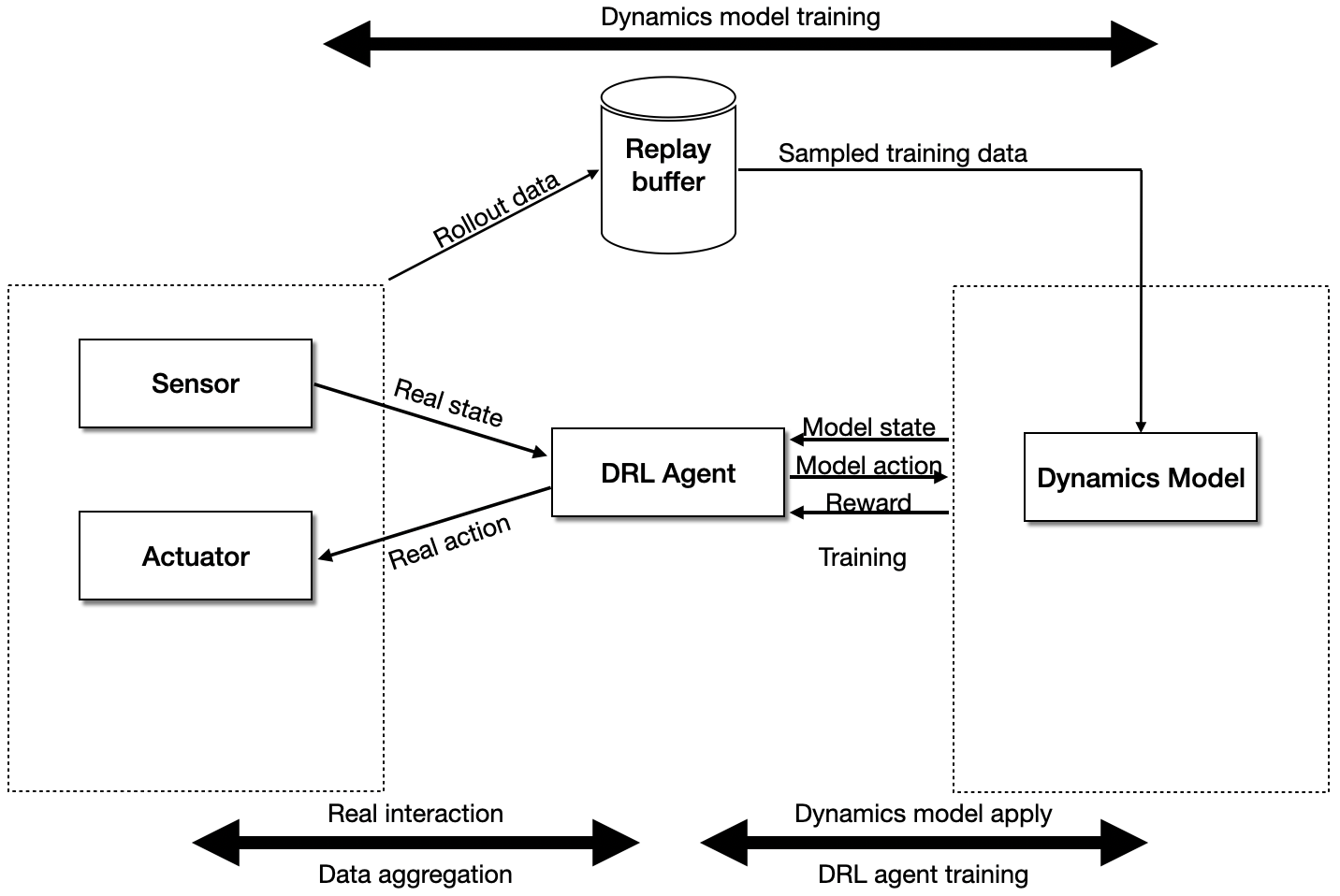
Due to the low system responsiveness, data efficiency was critical. We adopted a Dyna-like hybrid approach, combining:
- Model-based rollouts using the MDN
- Model-free updates to maintain stability
This approach resembles the SimPLe algorithm in spirit, where synthetic samples are leveraged to improve sample efficiency.
3. Safety-Aware Training
Because temperature violations can damage servers, we enforced strict hard constraints during training:
- Applied a safety margin below the actual temperature limit
- Introduced failure penalties when violations occurred
- Ended episodes early on failure and reset the environment using “manual full load cooling” (omitted from training data)
4. Overcoming the Cliff-Walking Problem
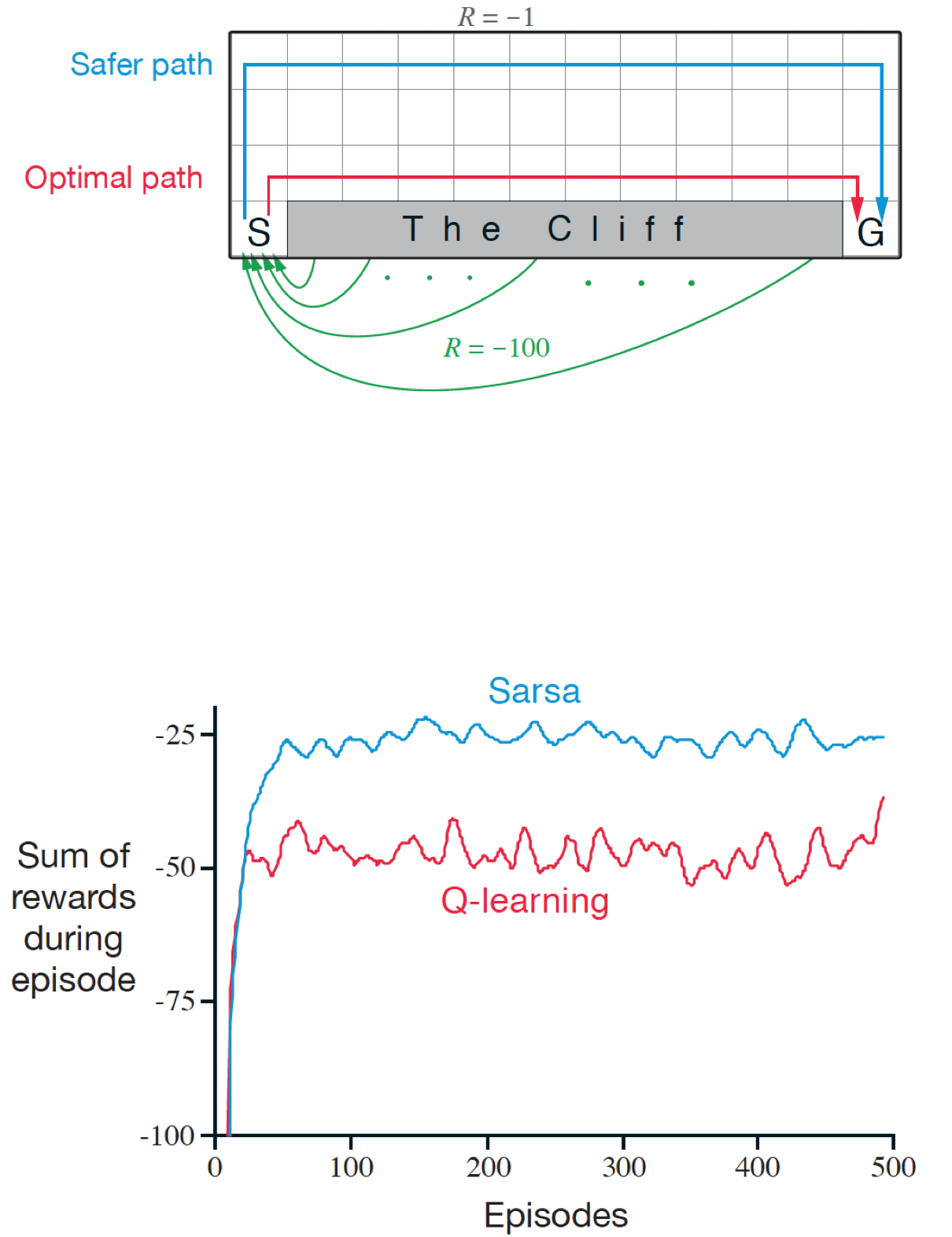
In traditional SARSA-style algorithms (unlike Q-learning-style algorithms), penalties from constraint violations propagate backward to earlier states, creating unstable learning dynamics. To counter this:
-
Modified the value function such that:
- if t < T-1 :
- if t = T-1 :
The Python code below implements a custom GAE mechanism that selectively blocks advantage propagation from failure penalties:
def selective_penalty_gae(rewards, values, dones, failed, gamma=0.99, lam=0.95):
"""
Custom GAE with:
- Normal reward propagation for success
- No propagation of failure penalty (only applied at failure step)
"""
T = len(rewards)
advantages = np.zeros(T)
lastgaelam = 0
for t in reversed(range(T)):
if dones[t]:
delta = rewards[t] - values[t]
if failed[t]:
lastgaelam = 0. # Failure: zero out GAE propagation
else:
lastgaelam = delta
advantages[t] = delta
else:
# Normal step: full GAE propagation
delta = rewards[t] + gamma * values[t + 1] - values[t]
lastgaelam = delta + gamma * lam * lastgaelam
advantages[t] = lastgaelam
return advantages
This significantly stabilized training by isolating failure signals to their causative actions only.
Results
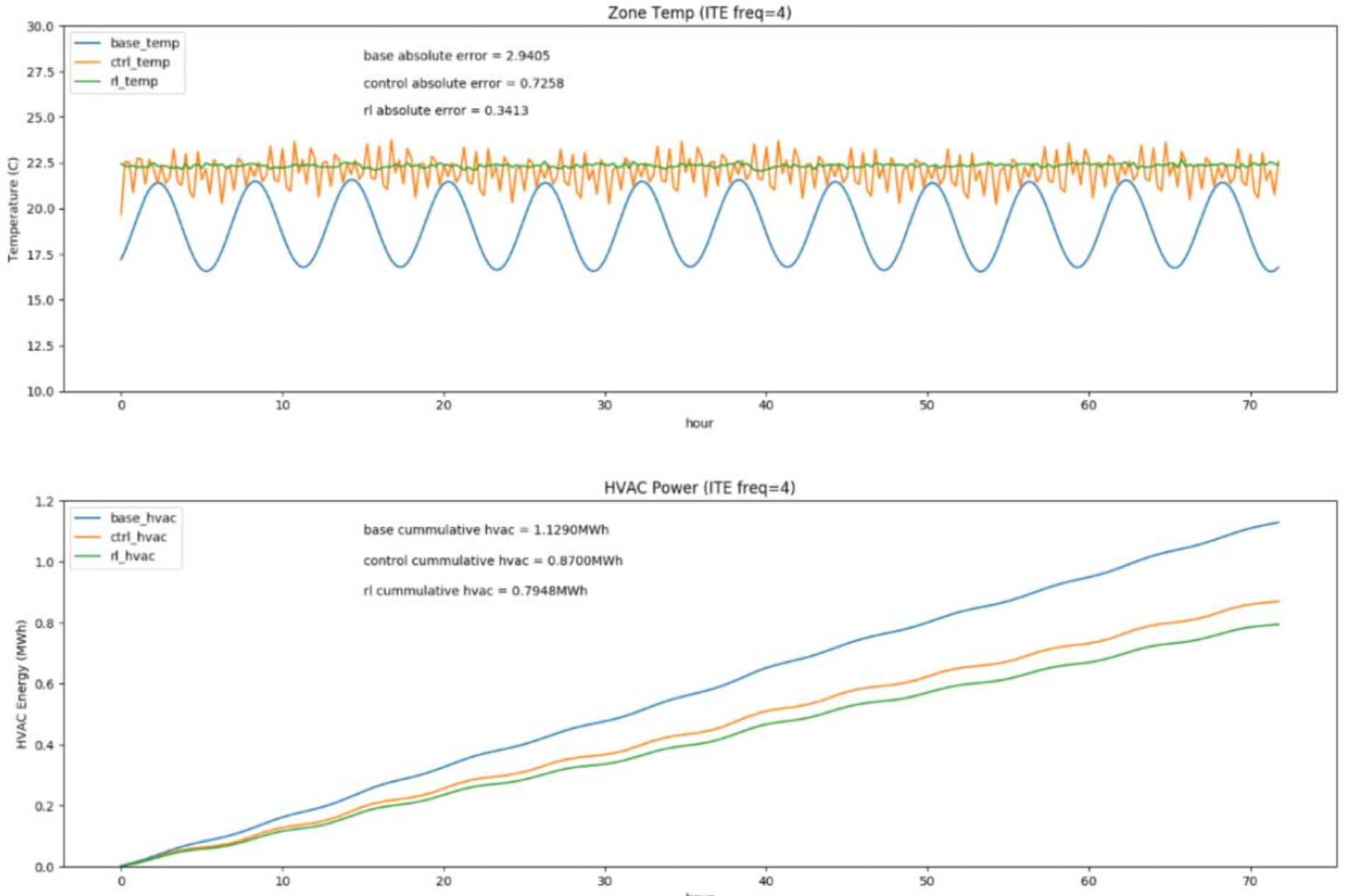
- Reduced the sample requirement from 30 years of simulated data (baseline) to 10 years, achieving a 3× improvement in sample efficiency.
- Achieved approximately 30% energy savings in simulation compared to the baseline control policy.
Retrospective
While the agent showed promising results in simulation:
- Deep neural dynamics models suffered from poor extrapolation, limiting robustness in unseen scenarios.
- Policy improvement steps introduced high variance, requiring conservative hyperparameter tuning.
- Sample efficiency was improved, but still insufficient for real-time deployment; we estimate at least 3 years of real-world training would be needed.
Although modifying the value function to suppress failure penalty propagation was effective in this project, more principled alternatives could also have been considered:
- Constrained Policy Optimization (CPO): Would have allowed explicit handling of constraint budgets without distorting reward propagation. In our case, where failure is rare but severe, CPO’s formulation could have maintained a clean separation between constraint violation signals and long-term value estimation.
- Safety Layer / Action Projection: Methods such as Control Barrier Functions (CBFs) could have ensured constraint satisfaction during both training and deployment, eliminating the need to inject failure penalties into the return at all.
- Lagrangian PPO: Incorporating a dynamic penalty multiplier (λ) into PPO’s objective could have helped learn a more robust balance between task reward and constraint cost.
These approaches are often more complex to implement or tune, but they offer better theoretical guarantees, clearer credit assignment, and better generalization, especially in safety-critical domains like data center control.
In future iterations, replacing heuristic value cutoffs with explicit constraint-aware optimization is expected to yield more robust and interpretable outcomes.
Related Resources
- EnergyPlus official sample used:
2ZoneDataCenterHVAC_wEconomizer.idf - World Models paper:
arXiv:1803.10122 - SimPLe:
arXiv:1903.00374
Closing Thoughts
This project demonstrated that reinforcement learning, when combined with model-based simulation, probabilistic modeling, and failure-isolated training techniques, can offer a practical pathway toward energy-efficient HVAC operation in data centers.
However, safe deployment in real-world environments will require broader integration of constraint-aware optimization and robust policy evaluation frameworks.