Domain Adaptation
Posted on
Practical Insights into Domain Adaptation: From Theory to Industrial Application
Introduction
When applying machine learning models in real-world environments, a common challenge is that the data used for training (source domain) often differs in distribution from the data encountered in deployment (target domain). This discrepancy, known as domain shift, can lead to significant performance degradation—sometimes up to 30%—in target domains.
Domain adaptation (DA) addresses this by learning domain-invariant representations, enabling models trained on the source domain to generalize effectively to the target domain. In this post, we first explore the theoretical foundations of DA by summarizing three influential methods:
- Domain-Adversarial Training of Neural Networks (DANN)
- Deep Reconstruction-Classification Network (DRCN)
- Associative Domain Adaptation (ADA)
We then connect these methods to real-world implementation insights from an actual research project conducted at Aidentify for ETRI (Electronics and Telecommunications Research Institute, Korea), where these algorithms were implemented, optimized, and evaluated on real industrial tasks.
What is Domain Adaptation?
Domain adaptation is a subfield of transfer learning where:
- The source domain has labeled data.
- The target domain has different data distribution (and often no labels).
- The label space is shared across domains.
Strategies include:
- Adversarial feature alignment
- Reconstruction-based representation sharing
- Similarity-based embedding association
- Explicit distribution matching (e.g., MMD, Wasserstein)
Theoretical Approaches
1. Domain-Adversarial Training of Neural Networks (DANN)
Key idea: Use adversarial training to learn features that are both discriminative (for the source task) and indistinguishable across domains.
Objective:
Mechanism:
- Feature extractor maps both domains to a shared space.
- Gradient reversal layer forces the feature extractor to confuse the domain classifier.
- Source and target distributions are aligned in feature space.
Industrial Insight:
In the ETRI project, I observed that DANN’s domain loss surged too quickly in early iterations, leading to poor convergence. We replaced the original half-hyperbolic tangent domain-loss envelope with a step-function envelope, significantly improving average classification accuracy from 71% to 79%.
2. Deep Reconstruction-Classification Network (DRCN)
Key idea: Jointly train the model to classify source samples and reconstruct both source and target samples using a shared encoder.
Objective:
Mechanism:
- A shared encoder maps both domains to latent space.
- A classifier predicts source labels.
- A decoder reconstructs inputs, aligning representations across domains.
Strength: Reconstruction-based alignment is often more stable than adversarial methods.
3. Associative Domain Adaptation (ADA)
Key idea: Align source and target embeddings by modeling probabilistic associations across domains and enforcing consistency in round-trip label propagation.
Step-by-step:
Let:
- : shared encoder
- : classifier
- : source data and labels
- : target data
1. Similarity-based association probability:
2. Soft label for target:
3. Walker loss (association consistency):
4. Visit loss (diversity regularization):
Final loss:
Field Insights from Industrial Deployment
This theoretical study was implemented in a real project:
Title: Software Implementation of Deep Learning-based Image Classification Model with Improved Domain Adaptation
Client: ETRI
Company: Aidentify
Duration: Sep–Oct 2018
Role: Sole researcher & developer
Key Findings
-
ADA outperformed DANN in classification accuracy across multiple benchmarks.
- This is consistent with ADA’s probabilistic modeling, which approximates true class distributions better when class distributions match.
- ADA’s use of KL divergence allows it to effectively “pull” similar embeddings together while pushing dissimilar ones apart.
- However, ADA assumes class distribution parity between source and target — an assumption that fails in real-world applications where target class frequencies are unknown and often skewed.
In real-world data, unlike MNIST or CIFAR-10, class imbalance in the target domain made ADA brittle. Sampling target batches to approximate source class balance was nontrivial due to unlabeled target data.
- Additionally, ADA is fundamentally tied to classification; it cannot easily generalize to regression or structured prediction tasks, unlike DANN.
Practical Modification to DANN
To address instability in DANN:
- Original issue: Domain loss ramped up too early, causing premature feature suppression.
- Fix: Replaced the smooth tanh-based envelope with a step-function envelope for the domain loss weight.
- Result: Boosted performance from 71% → 79% accuracy on internal benchmarks.
Comparison Table
| Method | Feature Alignment | Real-world Notes |
|---|---|---|
| DANN | Gradient reversal | Flexible, regression-compatible |
| DRCN | Reconstruction | Stable but indirect alignment |
| ADA | Round-trip association | High accuracy but brittle to imbalance |
Latent Representations: ADA vs. DANN
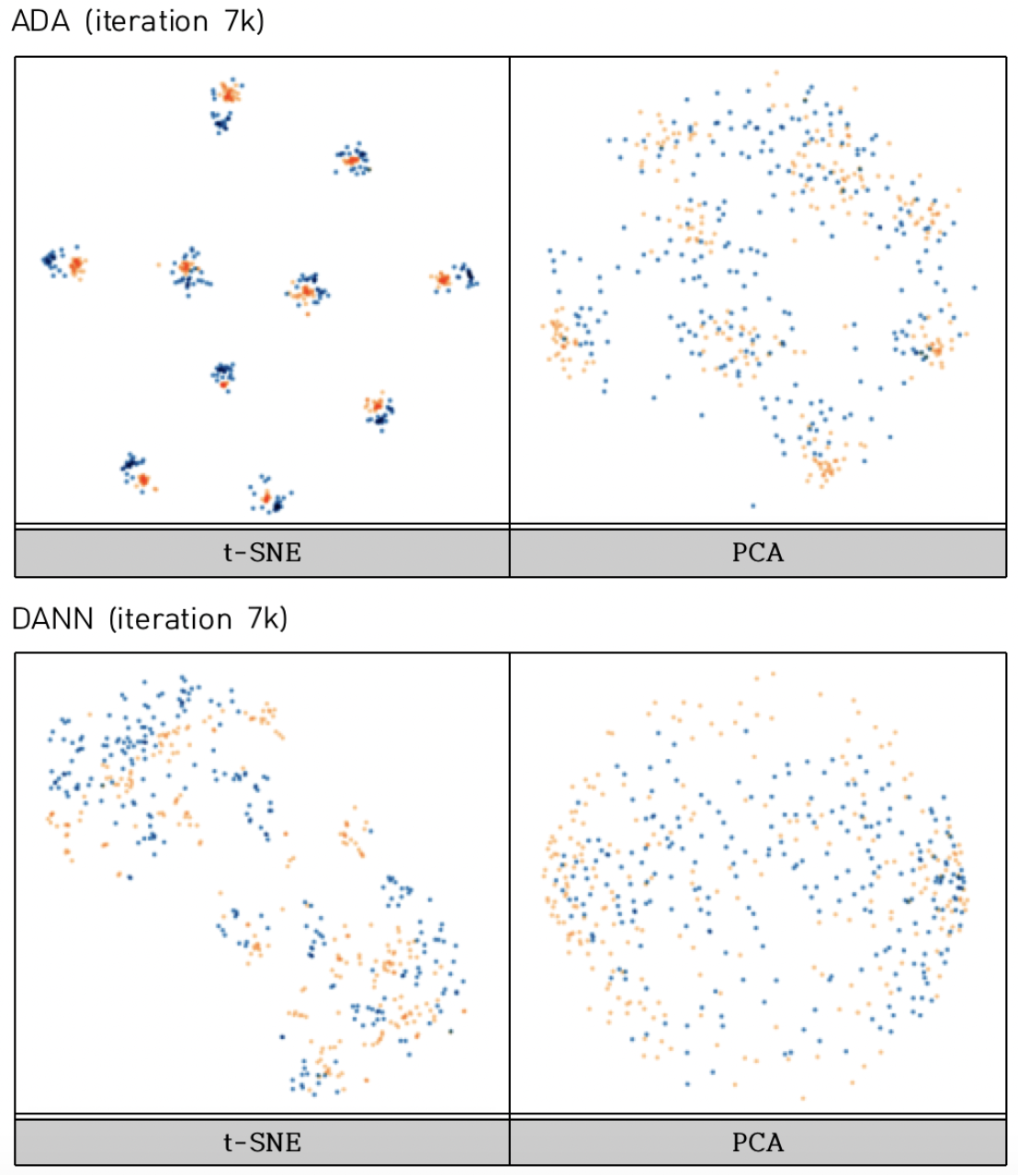
To further understand how different domain adaptation strategies shape the latent feature space, I visualized the embeddings produced by ADA and DANN at iteration 7k using both t-SNE and PCA projections.
ADA: Clear Cluster Formation with Class Consistency
In the ADA embedding space, t-SNE reveals compact and well-separated clusters. Each cluster clearly aligns with a distinct class, and importantly, both source (orange) and target (blue) samples are tightly co-located within the same clusters. This indicates that ADA not only promotes semantic alignment but also maintains class-level structural consistency across domains. PCA also shows a moderate separation between groups, though less pronounced due to its linear nature.
ADA’s round-trip association mechanism and class-conditional loss effectively guide the model to organize features around class identity, leading to highly interpretable and discriminative clusters in the shared latent space.
DANN: Domain Overlap but Weak Class Structure
In contrast, DANN’s t-SNE projection shows a coarse alignment of source and target distributions—the two domains are not fully separable, which indicates domain confusion is working as intended. However, within-domain class structure is not preserved: the embeddings are intermixed and lack distinct clustering.
PCA visualization of DANN reinforces this observation. The target domain has been roughly aligned with the source in global structure, but the absence of semantic grouping suggests that while domain alignment occurs, class-level discriminativeness is weaker.
DANN succeeds in domain-level alignment but fails to enforce tight intra-class cohesion, which can degrade classification accuracy on complex or imbalanced target domains.
Summary These visualizations provide empirical support for the earlier quantitative findings:
ADA excels at learning class-discriminative, domain-invariant features through its associative losses.
DANN promotes global domain confusion but may suffer from class ambiguity in the absence of explicit class-guided alignment mechanisms.
Conclusion
From both theoretical and experimental standpoints, ADA demonstrates strong performance when its assumptions hold, while DANN provides a more general and robust framework for industrial domain adaptation. Real-world deployment revealed critical mismatches between academic datasets and operational data—especially around class imbalance and unknown target distributions.
Industrial DA demands not just strong alignment, but resilience to class skew, task variation, and training stability. Hybrid methods that combine the stability of DANN with the probabilistic precision of ADA may offer the best path forward.
References
- Ganin, Y., et al. (2016). Domain-Adversarial Training of Neural Networks
- Ghifary, M., et al. (2015). Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation
- Haeusser, P., et al. (2017). Associative Domain Adaptation