Anomaly Detection
Posted on
Anomaly Detection
Overview
As part of a subcontracted PoC project with Hyundai Autron, I worked on developing a system to detect abnormal signals from internal combustion engines using time-series sensor data. The goal was to identify anomalies that may indicate potential engine malfunctions or sensor failures—without relying on pre-labeled abnormal data.
Problem Statement
- Input: Multivariate time-series sensor data from engine components.
- Goal: Distinguish between normal and abnormal operational patterns.
- Challenge: Only normal data was available for training. Anomalies had to be inferred in an unsupervised way.
Methodology
To address the lack of abnormal data and capture temporal dependencies in the signal, we applied the following pipeline:
1. LSTM-VAE for Time-Series Representation
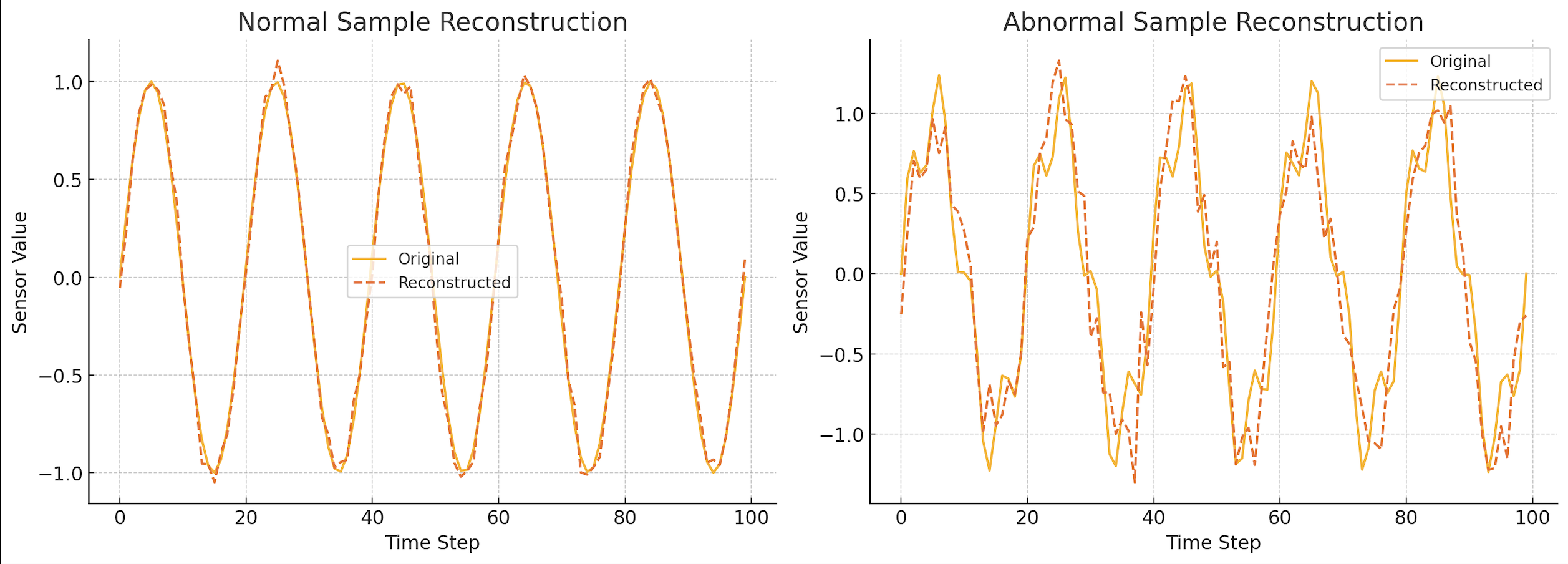
- We trained a Variational Autoencoder (VAE) whose encoder and decoder were based on LSTM networks to model sequential dependencies.
- Only normal engine data was used during training, under the assumption that the VAE would learn to reconstruct normal patterns well, but fail to reconstruct anomalous ones.
-
The VAE loss combined:
- Reconstruction loss (Mean Squared Error)
- KL divergence loss to regularize latent space distribution
2. Latent Space Clustering with SNE
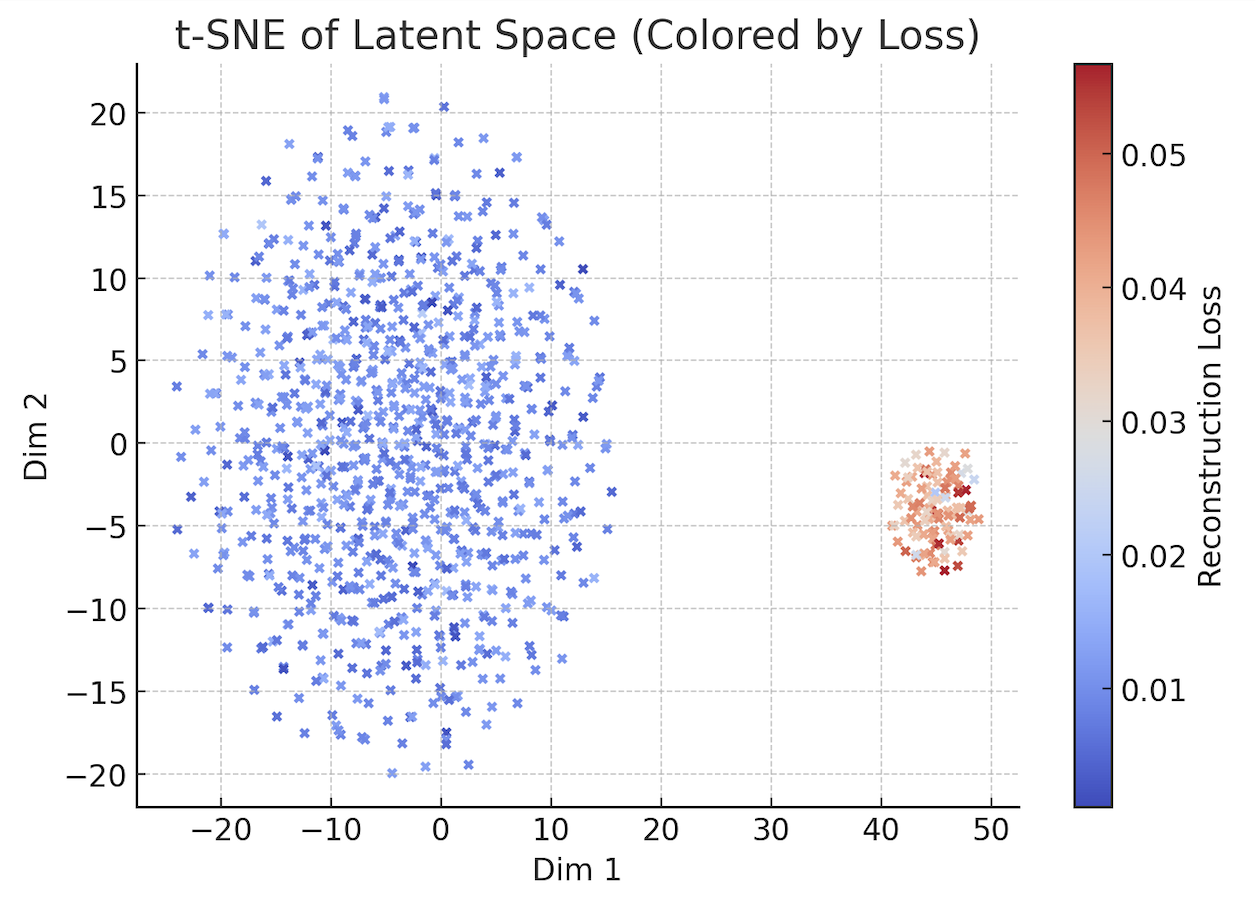
- After training, we passed both validation and test data through the VAE encoder to obtain latent vectors.
- We applied Stochastic Neighbor Embedding (SNE) to reduce the latent vectors to 2D for visualization and clustering.
-
Two main clusters consistently emerged:
- A compact, dense cluster of well-reconstructed samples
- A scattered, outlier cluster representing poorly reconstructed samples—likely anomalies
3. Label Inference and Thresholding
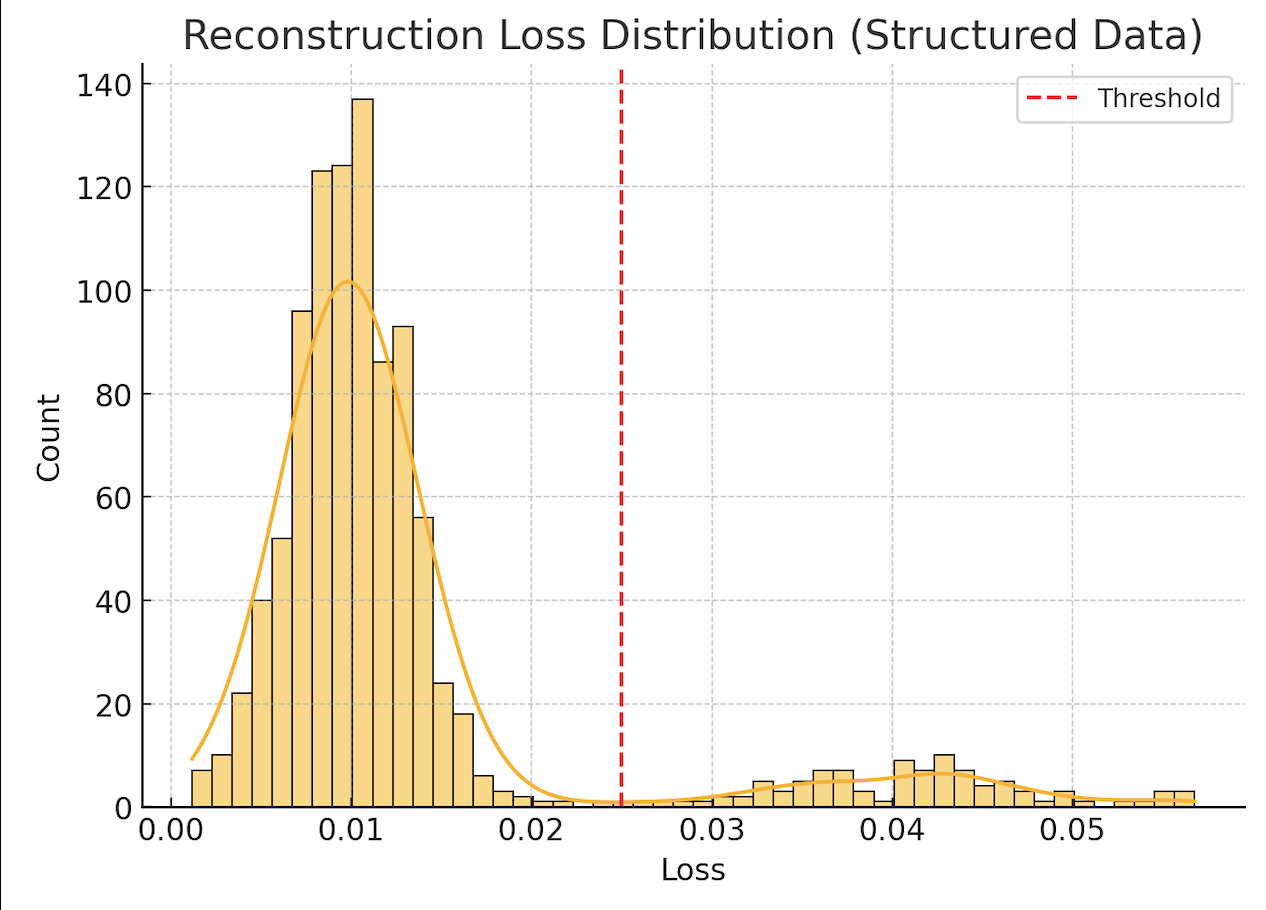
- By comparing the reconstruction error distribution and cluster assignments, we inferred the likelihood of a signal being anomalous.
- A soft threshold on the latent space distance and reconstruction loss was used to flag potential anomalies.
Results
-
On a validation set with synthetically injected anomalies:
- False Negatives were very rare
- False Positives did exist but were generally close to cluster boundaries or involved unusual (but not necessarily faulty) patterns
- The system was able to detect subtle deviations not easily visible in raw signal plots.
False Positive Analysis
- Many false positives occurred during transient engine states (e.g., rapid acceleration or deceleration)
- These patterns, while normal in context, were underrepresented in the training set, leading to over-sensitivity
- This revealed the importance of capturing complete operating conditions in the training data for unsupervised methods
Lessons Learned
- LSTM-VAE proved effective in modeling normal engine dynamics with minimal human labeling.
- Clustering in latent space via SNE enabled intuitive visualization and boundary identification.
- Data diversity is crucial: even a small omission of edge-case normal scenarios can inflate false positives.
- In high-stakes domains like automotive, low false negatives are preferable to low false positives—erring on the side of caution.
Service ResearchAnomaly DetectionUnsupervised LearningVariational AutoencoderStochastic Neighbor EmbeddingClustering